Leo Vogels
De laatste maanden is er ontzettend veel geschreven en gepraat over AI oftewel Artificial Intelligence. In de talkshows was het een komen en gaan van experts. Ook in TW gaan we méér aandacht gaan schenken aan AI. Dat wordt gewoon onderdeel van ons dagelijkse functioneren als ingenieurs. Microsoft gaat bijv. de ChatGPT deel uit laten maken van het Office pakket. Reden om dieper in te gaan op de ‘backstage’ van deze AI-ontwikkelingen. Dat doen we zonder in te gaan op de mathematische en statistische modellen die achter AI zitten. Ook zonder die modellen kunnen we de werking van AI (tekstgeneratie, gezichtsherkenning, beeldgeneratie/design, van gesproken stem naar woord of beeld etc) heel goed verklaren. In dit artikel gaan we in op een onderdeel van AI (Tekstgeneratie), wat als voorbeeld dient voor de overige AI toepassingen. 90% van de AI-software is namelijk niks anders dan een algemeen platform. De laatste 10% van de software zorgt ervoor dat er sprake is van specialistische functies zoals gezichtsherkenning, vertalen, CAD/CAM etc.
Magische zwarte doos
De release van ChatGPT door OpenAI eind vorig jaar is revolutionair geweest – zelfs mijn oma vraagt ernaar. De mogelijkheden om mensachtige taal te genereren hebben mensen geïnspireerd om te experimenteren met het potentieel ervan in verschillende producten. De enorm succesvolle lancering zette zelfs druk op techreuzen zoals Google om zich te haasten om hun eigen versie van ChatGPT uit te brengen.
Maar laten we eerlijk zijn, voor niet-technische productmanagers, ontwerpers en ondernemers lijkt de werking van ChatGPT misschien een magische zwarte doos. In dit artikel probeer ik de technologie en het model achter ChatGPT zo eenvoudig mogelijk uit te leggen. Aan het einde van dit bericht heb je een goed begrip van wat ChatGPT kan doen en hoe het zijn ‘magie’ uitvoert.
De transformator en GPT-tijdlijn
Voordat we diep ingaan op het eigenlijke mechanisme van ChatGPT, laten we eens kijken naar de tijdlijn van de ontwikkeling van de transformatorarchitectuur van taalmodellen en de verschillende versies van GPT, zodat je een beter idee krijgt van hoe dingen zijn geëvolueerd naar de ChatGPT die we vandaag hebben.
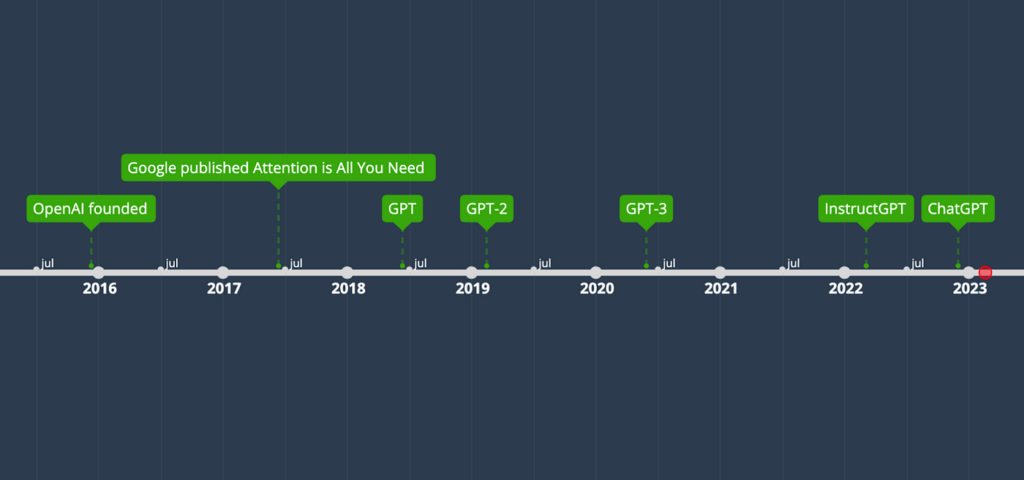
- 2015. OpenAI werd opgericht door Sam Altman, Elon Musk, Greg Brockman, Peter Thiel en anderen. OpenAI ontwikkelt veel verschillende AI-modellen verschillend van GPT.
- 2017. Introductie transformatorarchitectuur. De transformator is een neurale netwerkarchitectuur die de basis legt voor veel state-of-the-art (SOTA) grote taalmodellen (LLM, Large Language Models) zoals GPT.
- 2018. GPT-introductie. Het is gebaseerd op een aangepaste transformatorarchitectuur en vooraf getraind op een grote dataset.
- 2019. GPT-2 introductie. Deze kan een reeks taken uitvoeren zonder expliciet toezicht tijdens de training.
- 2020. GPT-3 model. Kan goed presteren met weinig voorbeelden in de prompt zonder fine-tuning.
- 2022. InstructGPT. Model dat gebruikersinstructies beter kan volgen door te finetunen met menselijke feedback.
- 2022. ChatGPT. Soort van broer of zus van InstructGPT. Het kan communiceren met mensen in gesprekken, dankzij de fine-tuning met menselijke voorbeelden en reinforcement learning van menselijke feedback (RLHF).
De tijdlijn laat zien dat GPT is geëvolueerd uit de oorspronkelijke transformatorarchitectuur en zijn kracht heeft verkregen via vele kleine stapjes. Als je de termen zoals transformatoren, pre-training, fine-tuning of reinforcement learning van menselijke feedback niet begrijpt: geen probleem. Ik zal ze allemaal uitleggen in de volgende secties.
Diep in de modellen duiken
Nu je weet dat ChatGPT is gebaseerd op transformatoren en de voorgaande GPT-modellen, laten we de componenten van die modellen eens nader bekijken en hoe ze werken. Het is oké als je niet bekend bent met deep learning, neurale netwerken of AI – ik zal de vergelijkingen weglaten en de concepten uitleggen met behulp van analogieën en voorbeelden.
In de volgende secties zal ik beginnen met een algemeen overzicht van taalmodellen en NLP, verdergaand naar de oorspronkelijke transformatorarchitectuur, vervolgens naar hoe GPT de transformatorarchitectuur heeft aangepast en ten slotte hoe ChatGPT is afgestemd op basis van GPT.
Taalmodellen en NLP
Er zijn veel soorten AI- of deep learning-modellen. Voor taken op het gebied van natuurlijke taalverwerking (NLP), zoals gesprekken, spraakherkenning, vertaling en samenvatting, zullen we gebruik maken van taalmodellen om ons te helpen.
Taalmodellen kunnen een bibliotheek van tekst (corpus) leren en woorden of reeksen woorden voorspellen met probabilistische verdelingen, d.w.z. hoe waarschijnlijk een woord of reeks kan voorkomen. Wanneer u bijvoorbeeld zegt “Tom eet graag …”, is de kans dat het volgende woord “pizza” is groter dan “tafel”. Als het een volgend woord in de reeks voorspelt, wordt het ‘next-token-prediction’ genoemd; als het een ontbrekend woord in de reeks voorspelt, wordt het gemaskeerde taalmodellering genoemd.
Omdat het een kansverdeling is, kunnen er veel waarschijnlijke woorden zijn met verschillende waarschijnlijkheden. Hoewel je misschien denkt dat het ideaal is om altijd de beste kandidaat met de hoogste waarschijnlijkheid te kiezen, kan dit leiden tot repetitieve sequenties. Dus in de praktijk zouden onderzoekers wat willekeur (temperatuur) toevoegen bij het kiezen van het woord uit de topkandidaten.
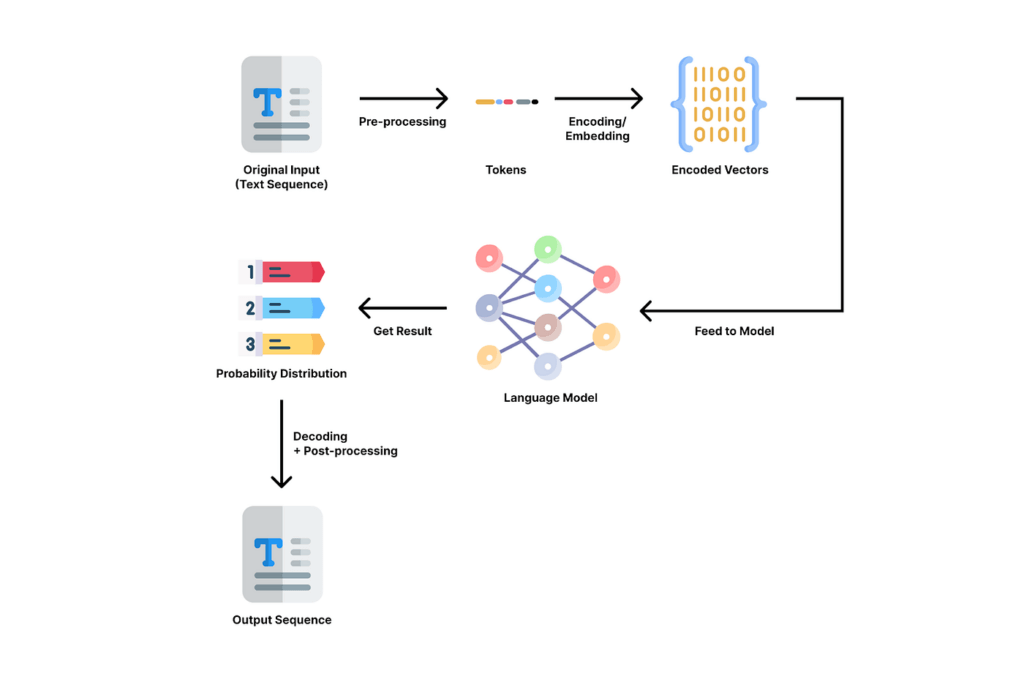
In een typisch NLP-proces doorloopt de invoertekst de volgende stappen:
- Voorbewerking: het opschonen van de tekst met technieken als zinsherkenning, tokenisatie (de tekst opsplitsen in letters die tokens worden genoemd), stemming (de ‘stam’ van een woord vinden), het verwijderen van stopwoorden, het corrigeren van spelling, enz. “Tom eet bijvoorbeeld graag pizza.” zou worden getokeniseerd in [“Tom”, “likes”, “to”, “eat”, “pizza”, “.”] en in [“Tom”, “like”, “to”, “eat”, “pizza”, “.”].
- Coderen of ‘embedding’: verander de opgeschoonde tekst in een vector van getallen, zodat het model kan zijn werk kan doen.
- Invoer naar model: geef de gecodeerde invoer door aan het model voor verwerking.
- Resultaat krijgen: krijg een output van een kansverdeling van potentiële woorden weergegeven in vectoren van getallen uit het model.
- Decoderen: vertaal de vector terug naar voor mensen leesbare woorden.
- Nabewerking: verfijn de uitvoer met spellingcontrole, grammaticacontrole, interpunctie, hoofdlettergebruik, enz.
AI-onderzoekers hebben veel verschillende modelarchitecturen bedacht. Transformers, een soort neuraal netwerk, is de afgelopen jaren state-of-the-art en legt de basis voor GPT. In de volgende sectie zullen we kijken naar de componenten en mechanismen van transformatoren.
De ‘Transformer’ architectuur
De transformatorarchitectuur is de basis voor GPT. Het is een soort neuraal netwerk, dat vergelijkbaar is met de neuronen in ons menselijk brein. De transformator kan contexten in sequentiële gegevens zoals tekst, spraak of muziek beter begrijpen met mechanismen die ‘attention’ en ‘selfattention’ worden genoemd.
Attention stelt het model in staat om zich te focussen op de meest relevante delen van de input en output door de relevantie of gelijkenis tussen de elementen te leren, die meestal worden weergegeven door vectoren. Als het zich op dezelfde woordgroep richt, wordt het self-attention genoemd.

Laten we de volgende zin als voorbeeld nemen: “Tom likes to eat apples. He eats them every day”. In deze zin verwijst “he” naar “Tom” en “them” naar “apples”. En het aandachtsmechanisme gebruikt een wiskundig algoritme om het model te vertellen dat die woorden gerelateerd zijn door een gelijkenisscore tussen de woordvectoren te berekenen. Met dit mechanisme kunnen transformatoren de betekenissen in de tekstreeksen op een meer coherente manier “begrijpen”.
Transformatoren hebben de volgende componenten:
- Embedden en positionele codering: woorden omzetten in vectoren van getallen
- Encoder: extraheer kenmerken uit de invoervolgorde en analyseer de betekenis en context ervan. De output is een matrix met ‘hidden states’ (mogelijke waarden van variabelen) voor elk ingevoerd token. Dat zijn dus matrices met gigantische afmetingen!
- Decoder: genereer de woordgroepvolgorde op basis van de uitvoer van de encoder en de vorige uitvoertokens
- Lineaire en Softmax-laag: de vector omzetten in een kansverdeling van uitvoerwoorden op basis van de gekozen optimalisatiefunctie
De encoder en decoder zijn de belangrijkste componenten van de transformatorarchitectuur. De encoder is verantwoordelijk voor het analyseren en “begrijpen” van de invoertekst en de decoder is verantwoordelijk voor het genereren van uitvoer.
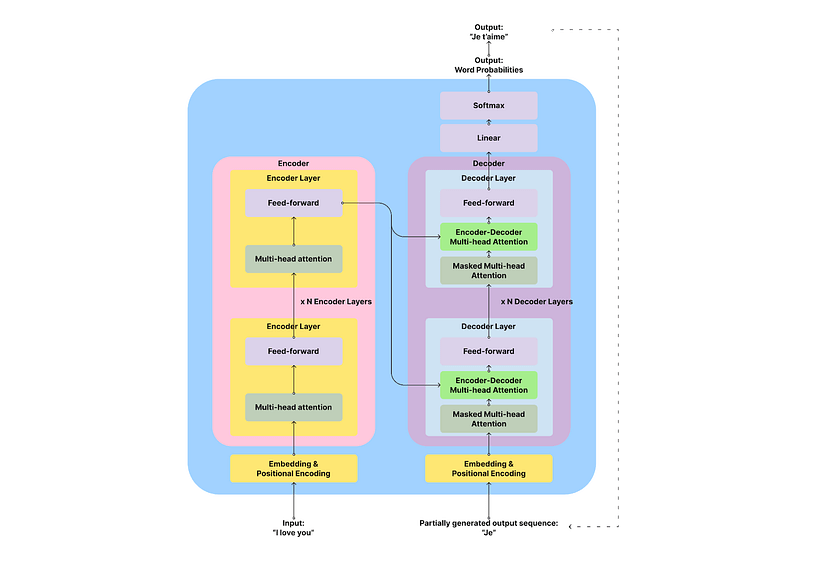
Hieronder volgen de technische details van encoders en decoders. Wanneer je snel door wilt lezen ga dan door naar de volgende paragraaf over GPT.
De encoder is een opeenstapeling van meerdere identieke lagen (6 in de originele transformatorsoftware). Elke laag heeft twee sublagen: een meerkoppige selfattention-laag en een feed-forward laag. De multi-head self-attention sub-layer past het attention mechanisme toe om het raakvlak/ de gelijkenis tussen invoertokens te vinden om de invoer te begrijpen. De feed-forward sublaag past enkele datastappen toe voordat het resultaat naar de volgende laag wordt doorgegeven. Je kunt encoders zien als het lezen van boeken – je besteedt aandacht aan elk nieuw woord dat je leest en denkt na over hoe het gerelateerd is aan de vorige woorden.
De decoder is vergelijkbaar met de encoder in die zin dat het ook een opeenstapeling van identieke lagen is. Maar elke decoderlaag heeft een extra encoder-decoder aandachtslaag tussen de self-attention en feed-forward lagen, zodat de decoder toegang heeft tot de ingangsvolgorde. Als je bijvoorbeeld “Ik hou van je” (invoer) vertaalt naar “Je t’aime” (uitvoer), moet je weten dat “Je” en “ik” bij elkaar horen en “liefde” en “aime” bij elkaar horen. Juist deze stap was een doorbraak in de probabilistische taalmodellen. Dit zorgt voor de coherente structuur van de teksten!
De meerkoppige aandachtslagen in de decoder zijn ook anders dan in de encoder. Ze zijn gemaskeerd om niets rechts van het huidige token te doen, dat nog niet is gegenereerd. Je kunt decoders zien als schrijven in vrije vorm – je schrijft op basis van wat je hebt geschreven en wat je hebt gelezen, zonder je zorgen te maken over wat je gaat schrijven.
Van transformatoren naar GPT, GPT2 en GPT3
De volledige naam van GPT is Generative Pre-trained Transformer. Aan de naam kun je zien dat het een generatief model is, goed in het genereren van output; het is vooraf getraind, wat betekent dat het heeft geleerd van een groot corpus van tekstgegevens; het is een type transformator.
In feite gebruikt GPT alleen het decodergedeelte van de transformatorarchitectuur. Uit de vorige transformatorsectie hebben we geleerd dat decoders verantwoordelijk zijn voor het voorspellen van het volgende token in de reeks. GPT herhaalt dit proces keer op keer door de eerder gegenereerde resultaten als invoer te gebruiken om langere teksten te genereren, wat autoregressief wordt genoemd. Als het bijvoorbeeld “Ik hou van je” naar het Frans vertaalt, genereert het eerst “Je” en gebruikt het vervolgens de gegenereerde “Je” om “Je t’aime” te krijgen. (Zie de stippellijn in de vorige afbeelding).
Bij het trainen van de eerste versie van GPT gebruikten onderzoekers ‘unsupervised’ pre-training met de BookCorpus-database, bestaande uit meer dan 7000 unieke ongepubliceerde boeken. Unsupervised learning is alsof de AI die boeken zélf leest en probeert de algemene regels van taal en woorden te leren. Naast de pre-training gebruikten ze ook ‘supervised’ fine-tuning op specifieke taken zoals samenvatten of vragen en antwoorden. Supervised betekent dat ze het model voorbeelden van prompts/vragen en de correcte antwoorden laten zien en de AI vragen om van die voorbeelden te leren.
In GPT-2 breidden de onderzoekers de grootte van het model (1,5B parameters) en het corpus dat ze aan het model voeden uit met WebText, een verzameling van miljoenen webpagina’s. Met zo’n groot corpus om van te leren, bewees het model dat het zeer goed kan presteren binnen een breed scala aan taalgerelateerde taken, zelfs zonder ‘supervised’ fine-tuning.
In GPT-3 gingen de onderzoekers een stap verder in het uitbreiden van het model naar 175 miljard parameters en het gebruik van een enorm corpus bestaande uit honderden miljarden woorden van het web, boeken en Wikipedia. Met zo’n enorm model en een groot corpus in de trainingsset, ontdekten onderzoekers dat GPT-3 kan leren om taken beter uit te voeren met één (one-shot) of een paar voorbeelden (few-shot) in de prompt zonder expliciete supervised fine-tuning.
In dit stadium is het GPT-3-model al indrukwekkend. Onderzoekers wilden onderzoeken hoe het menselijke instructies kan volgen en gesprekken met mensen kan voeren. Daarom hebben ze InstructGPT en ChatGPT gemaakt op basis van het algemene GPT-model.
GPT leren om met mensen te communiceren: InstructGPT en ChatGPT
Na de ontwikkeling van GPT naar GPT-3 met groeiende modellen en corpusgrootte, realiseerden onderzoekers zich dat grotere modellen niet betekenen dat ze de menselijke bedoeligen goed kunnen volgen. Daarom probeerden ze GPT-3 te verfijnen met supervised learning en reinforcement learning from human feedback (RLHF). Met deze trainingsstappen kwamen de twee finetuned modellen – InstructGPT en ChatGPT.
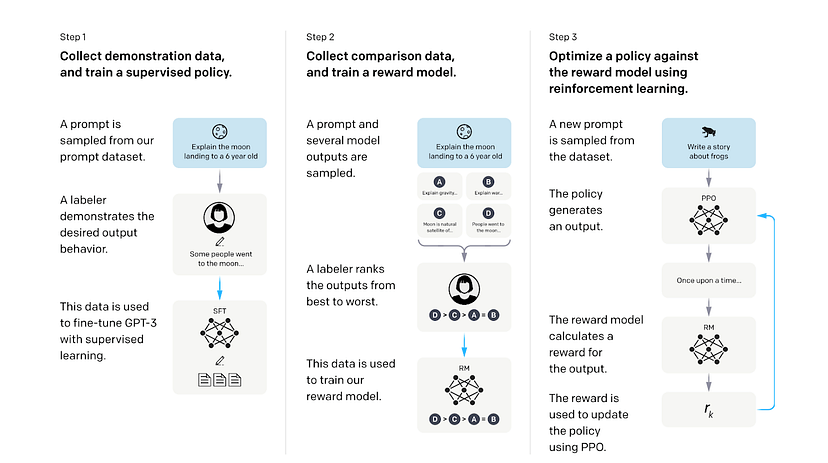
De eerste stap is supervised leren van menselijke voorbeelden. Onderzoekers voorzagen de vooraf getrainde GPT eerst van een samengestelde, gelabelde dataset van prompt- en responsparen geschreven door menselijke labelers. Deze dataset wordt gebruikt om het model het gewenste gedrag uit die voorbeelden te laten leren. Deze stap resulteert in een supervised fine-tuned (SFT) model.
De tweede stap is het trainen van een beloningsmodel (RM, Reward Model) om de reacties van het generatieve model te beoordelen. Onderzoekers gebruikten het SFT-model om meerdere antwoorden van elke prompt te genereren en vroegen menselijke labelers om de antwoorden van beste naar slechtere te rangschikken op kwaliteit, betrokkenheid, informatie, veiligheid, samenhang en relevantie. De prompts, antwoorden en ranglijsten worden vervolgens gevoed aan een beloningsmodel om menselijke voorkeuren van de reacties te leren door middel van supervised leren. Het beloningsmodel kan een beloningswaarde voorspellen op basis van hoe goed de respons overeenkomt met menselijke voorkeuren.
In de derde stap gebruikten onderzoekers het beloningsmodel om het beleid van het SFT-model te optimaliseren door middel van reinforcement learning. Het SFT-model genereert een reactie op basis van een nieuwe prompt; het beloningsmodel beoordeelt de respons en geeft deze een beloningswaarde die de menselijke voorkeur benadert; de beloning wordt vervolgens gebruikt om het generatieve model te optimaliseren door de parameters van het model bij te werken. Als het generatieve model bijvoorbeeld een reactie genereert waarvan het beloningsmodel denkt dat mensen het leuk vinden, krijgt het een positieve beloning om in de toekomst vergelijkbare reacties te blijven genereren; en andersom.
Door dit proces van supervised learning en reinforcement learning met menselijke feedback, is het InstructGPT-model (met slechts 1,3B parameters) in staat om beter te presteren in taken die volgen uit menselijke instructies dan het veel grotere GPT-3-model (met 175 B-parameters).
ChatGPT is een zustermodel van InstructGPT. Het trainingsproces is vergelijkbaar voor ChatGPT en InstructGPT, inclusief dezelfde methoden van supervised leren en RLHF die we eerder hebben behandeld. Het belangrijkste verschil is dat ChatGPT is getraind met voorbeelden van gesprekstaken, zoals het beantwoorden van vragen, chit-chat, trivia, enz. Door deze training kan ChatGPT gesprekken voeren met mensen in dialogen. In gesprekken kan ChatGPT vervolgvragen beantwoorden en fouten toegeven, waardoor het boeiender wordt om mee te communiceren.
Samenvatting
Als een korte samenvatting, zijn hier de belangrijkste zegeningen en beperkingen van GPT-modellen:
- ChatGPT is gebaseerd op een decoder-only auto-regressief transformatormodel om een woordengroep op te nemen en een kansverdeling van tokens in de komende reeks uit te voeren, waarbij één token tegelijk iteratief wordt gegenereerd.
- Omdat het niet de mogelijkheid heeft om in realtime naar referenties te zoeken (bijvoorbeeld op het Internet), doet het probabilistische voorspellingen in het generatieproces op basis van het corpus waarop het is getraind, wat kan leiden tot valse beweringen over feiten.
- Het is vooraf getraind op een enorm corpus van web- en boekgegevens en afgestemd op menselijke gespreksvoorbeelden door middel van supervised learning en reinforcement learning van menselijke feedback (RLHF).
- Zijn vermogen is voornamelijk gebaseerd op de modelgrootte en de kwaliteit en grootte van het corpus en voorbeelden waarvan het heeft geleerd. Met wat extra supervised learning of RLHF kan het beter presteren in specifieke contexten of taken.
- Omdat het corpus afkomstig is van webinhoud en boeken, kunnen de trainingssets vooroordelen hebben waar het model van leert. Dit kan leiden tot vooroordelen in de output op het gebied van cultuur, politiek, geslacht etc.
Blijf nieuwsgierig en sta open voor nieuwe technologieën zoals ChatGPT. Ik geloof dat een open mindset en nieuwsgierigheid ons (ontwerpers, ingenieurs, digital marketeers en ondernemers) kunnen helpen bij het navigeren door deze nieuwe golf van technologische revolutie.











